A Deeper Look at the MACRO Score (Part 1)
An in-depth look at the intricacies of the MACRO Score. Our data science team details how they defined the problem, gathered data, engineered features, and constructed a model. Part one of two.

This blog is the beginning of an in-depth explanation of the mechanics and data science powering the MACRO Score. Here, we cover the end-to-end machine learning pipeline, beginning with data collection and feature engineering. Part 2 will explore model evaluation criteria, MACRO Score computation, interpreting MACRO Scores, and monitoring the models.
Defining the Problem
The MACRO Score is a numerical representation of a person’s on-chain creditworthiness. Creditworthiness, in traditional finance, is the assessment of an individual or a corporate entity’s predicted probability of default, represented through a credit score and credit rating, respectively. Default refers to a borrower’s failure to repay their debt obligations within a stipulated time.
However, the concept of default does not exist in Decentralized Finance (DeFi), where borrowing is inherently more fluid than in traditional finance. Multiple loans may be made with no fixed repayment schedule, all of which can be repaid at once or through multiple repayments of varying amounts over an extended period.
DeFi lending protocols require a minimum collateral level to be maintained by borrowers, known as the health factor (calculated as the ratio of the value of collateral to loan amounts). Suppose a borrower’s health factor drops below 1. In that case, their open debt positions can be liquidated by a liquidator, with the sale proceeds being used to repay the loan obligation to the lending protocol. Given the volatile nature of various cryptocurrencies, borrowers need to ensure the value of their provided collateral does not drop or the outstanding loan value does not increase by such an extent to put them at the risk of liquidation.
Creditworthy DeFi borrowers aim to maintain a reasonable headroom in their health factors to avoid liquidations and loss of capital. Accordingly, creditworthiness in DeFi is an assessment of the predicted probability of liquidation—the higher the probability of liquidation (i.e., high-risk borrower), the lower the MACRO Score, and vice versa.
Gathering Data
Given the open-source nature of the blockchain, we can collect and extract a substantially broad and deep dataset. We aim to include all transactions executed on all the leading lending protocols since their respective genesis.
During our Open Beta Launch, our three main data sources were:
- All transactions ever recorded on the two leading DeFi lending protocols: Compound and Aave (v1 and v2 of both on Ethereum). Such transactions include borrows, repayments, deposits, redemptions, and liquidations and go back to Sep 2018.
- Ethereum transactional data, e.g. token/ERC-20 transfers. These transactions go as far back as August 2015 (i.e., just after the Ethereum genesis block).
- Various other public APIs for historical token prices in ETH. These historical token prices are then used to convert all transaction amounts, token balances, etc. into ETH to allow for consistent analyses irrespective of the underlying transaction token.
Our starting list of all historical borrow transactions had two types of borrowers that were dealt with differently:
- Transactions initiated by Externally Owned Accounts (EOAs)— no further processing required.
- Transactions initiated by smart contracts. For such transactions, we trace back through the transaction chain to identify the EOA that initiated the transaction; and re-assign the transaction(s) to that EOA.
Thus, our training dataset consisted entirely of borrowings made by EOAs. We excluded smart contracts from the dataset since our objective is to provide on-chain credit scores for individuals (to allow for real-life use cases and composability).
Feature Engineering
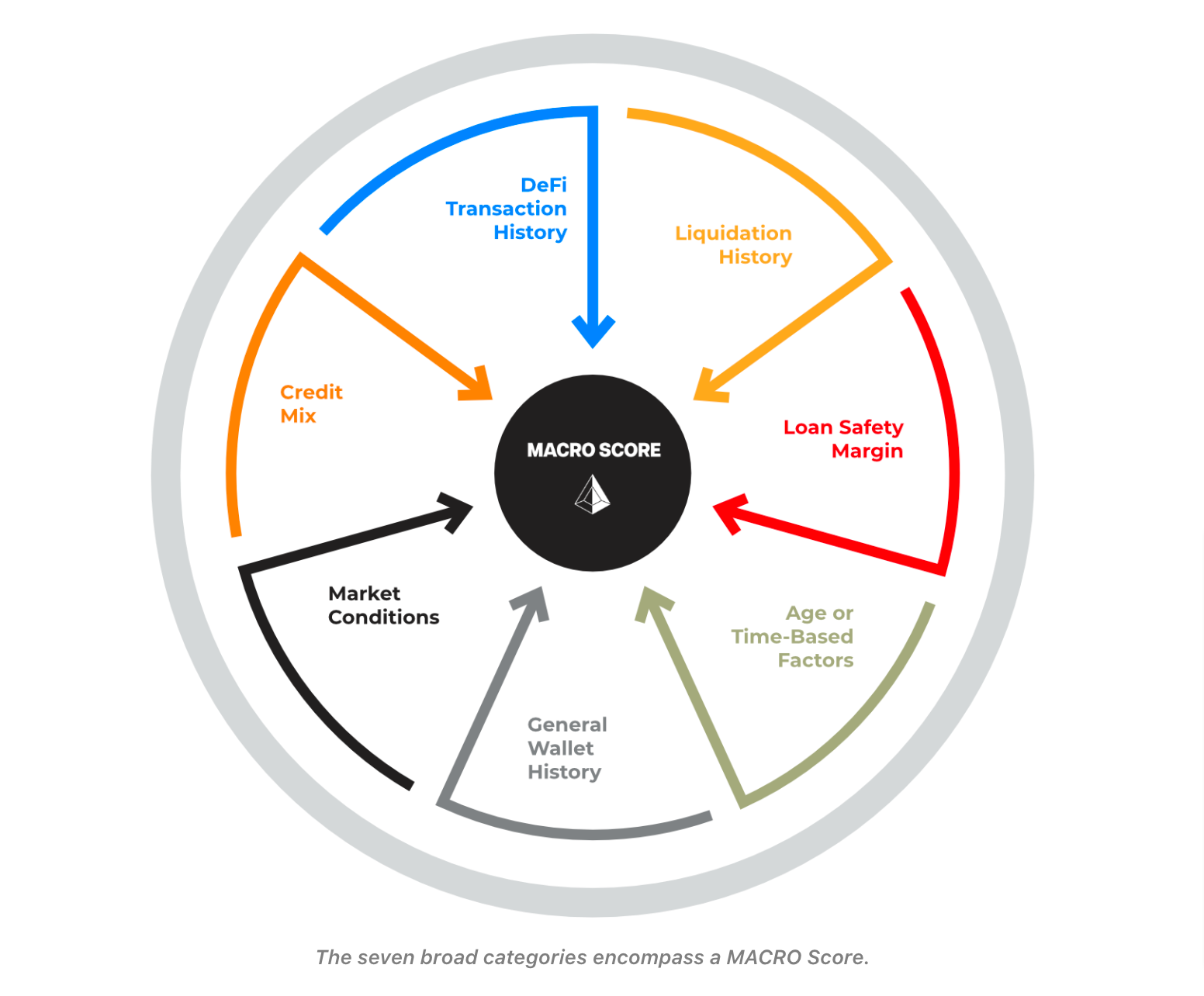
The raw transactional dataset was then used to create the starting set of almost 100 features, categorized by the following seven ingredients.
1. DeFi Transaction History
DeFi transaction history encapsulates one's interactions with DeFi lending protocols regarding borrowing, repayment, deposits, and redemptions. These individual transaction types are summarized and aggregated as follows:
- Counts
- Current and historical time-weighted outstanding loan balance
- Historical time-weighted net amounts deposited (deposits net of redemptions)
2. Liquidation History
The MACRO Score uses liquidation as a proxy for loan default. A higher appetite for risk translates into less creditworthiness or a flag for speculative behavior. Therefore, we evaluate the frequency and amount of past liquidations.
3. Loan Safety Margin
Similar to the loan-to-value (LTV) ratio in traditional finance, Spectral evaluates the amount of headroom maintained as part of one’s borrowing activities. The higher the level of collateralization (generally referred to as the health factor), the more risk-averse a user tends to be, improving the MACRO Score.
Instead of assessing the health factor, Spectral evaluates its reciprocal, aptly called the risk factor, purely for the ease of computation. Some examples of features include:
- Current risk factor
- Historical average risk factor
- Historical weighted average risk factor
- Maximum risk factor ever recorded in the past
- Number of times a user’s risk factor hovered around the liquidation threshold
- Amount of collateral provided
4. Age or Time-Based Factors
The MACRO Score also evaluates whether a user has an established and reasonably long history of DeFi and on-chain interactions and activities. Older wallets can be expected to have higher MACRO Scores so long as they have maintained a reasonably clean credit history.
We consider the following factors:
- Length of credit history
- Length of lending history
- Earliest liquidation event
- Age of the wallet
- Timestamps of the first and last transactions
5. General Wallet History
Analysis of a user’s wallet history provides supplemental insights into a user's on-chain behavior and covers the following:
- Current wallet balance
- Historical minimum and maximum wallet balances
- Historical time-weighted wallet balances
- Wallet composition in terms of stablecoins and top coins by market capitalization - both current and historical time-weighted
- Count of wallet transactions
6. Market Conditions
Spectral evaluates general market volatility through various technical indicators. Undertaking risky borrowing transactions during volatile or uncertain market conditions is not advised. Therefore, the prevailing market conditions at the time of one’s historical DeFi activities as well as at the time of scoring are taken into consideration by the MACRO Score.
7. Credit Mix
The MACRO Score considers the mix of DeFi lending protocols a user has interacted with. Although a diversified credit mix (in terms of the number of DeFi protocols interacted with) is not required for a high MACRO Score, it is generally advisable to interact with various DeFi lending protocols to spread one's risk.
Factors covered include:
- Count of protocols ever interacted with
- Count of protocols a user has ever lent to or borrowed from, in the past
- Maximum monetary concentration in terms of borrowing and lending activities in a single protocol
Constructing the Model
Dataset for Model Training and Validation
Spectral’s dataset at the time of writing includes all borrow transactions recorded on Compound and Aave (v1 and v2 of both on Ethereum) since their inception and up to April 2022. Restricting the last observation date to April 2022 allows us to look into the future while standing in the past to determine the ground truth label (i.e., the target) for all the observations.
After sorting by the transaction timestamp, the data is partitioned into train and test datasets to allow for both out-of-sample and out-of-time validation on the test data. As an example, a model trained on observations up to Sep 2021 can be used to make predictions on data from Oct 2021 - Apr 2022 and thereafter evaluated and validated on these predictions.
The train set is then partitioned into ten folds to allow for further time-based cross-validation to search for the best model.

Target Definition
The MACRO Score aims to predict future liquidations. Therefore, our binary target variable is one if:
- A borrower was liquidated within ℓ days of taking out a DeFi loan (we take ℓ = 60); or
- A borrower’s risk factor was recorded higher than the liquidation threshold adjusted to capture more risky open positions within ℓ days of taking out a DeFi loan.
We refer to the above target definition as the hybrid target to differentiate it from other target definitions we employ in other candidate models. Including the risk factor as part of the hybrid target definition allows us to capture risky (i.e., close to being liquidated) positions together with those that, although technically eligible to be liquidated, were not liquidated.
Feature Selection
To feed the machine learning algorithms with only the most relevant, high-quality, and highly predictive set of features, several iterations are performed through the following approaches:
- Correlation Evaluation: Features that exhibit high correlations with others (determined through Pearson correlation coefficient and VIF) are excluded or otherwise dealt with to eliminate collinearity. This ensures that no two features represent the same information value that could impact the interpretability of our final model. The decision to drop one of the two correlated features is taken in light of the F-Statistic feature importances of the two with the target.
- Variance Analysis: Features with a very low variance among observations do not add any value to the predictive power of a model and are accordingly excluded.
Features are also dropped when, post model training, an analysis of the Partial Dependence Plot (PDP) reveals that the relationship between a particular feature and the target is illogical.
Combining the above approaches enables us to short-list the most suitable features required for credit risk assessment without compromising the model's performance.
Model Training
Tree-based and gradient-boosting machine learning algorithms were used in the modeling exercise. Multiple candidate models were trained and evaluated that differed from each other in terms of:
- Target definition: hybrid target or not
- Feature handling: treating certain features as numerical vs categorical
- Feature combination: using a different subset of features
The various hyperparameters of these candidate models, tuned via Bayesian search, were evaluated through time-based 10-fold cross-validation. Each candidate model was preliminarily evaluated in terms of its soundness, feature importance, and PDPs for each constituent feature before being qualified for a more formal model evaluation.
Part 2 of our Deeper Look at the MACRO Score will cover topics such as model evaluation criteria, computation of the MACRO Score, interpreting MACRO Scores, and ongoing model monitoring. Stay tuned!
For a non-technical primer/overview, please read our Introduction to the MACRO Score.
Are you a developer and would like early access to our Scoring APIs and smart contracts?