The Emergence of Data Science in Web3
Spectral’s MACRO Score helped prove a critical mass of blockchain data is available for analysis. Find out how technologies like zero-knowledge machine learning (zkml), verifiable computing, and competitive machine learning are creating new use cases for on-chain data.

The first of a series on The Evolution of Data Science in Web3, exploring the convergence between data science and on-chain data: With a million transactions a day executing on the Ethereum blockchain, and millions more on Layer 2s, an enormous amount of data has accumulated. This parallels the exponential growth of data from social media and online commerce during the first two decades of the 21st century and offers enormous opportunities for Web3 protocols.
From Heavenly Data Hoarding to Spectral’s Decentralized Machine Learning
Hven, a tiny isle located midway between Sweden and Denmark was once home to the world’s most valuable data hoard: data recording the transit of stars and planets that the 16th Century astronomer Tycho Brahe observed peering at the night sky. He jealously guarded this hoard, releasing tiny dribbles of information during his lifetime. He left the island near the end of his life, and moved to Prague, where, after Brahe’s death, Johann Kepler finally got unfettered access to decades' worth of data following the planet Mars allowing him to notice eccentricities and postulate new rules for planetary motion, which helped set the foundation for Galileo’s evidence for a heliocentric solar system, and, according to Steve Brunson, a professor at the University of Washington, inspired Newton’s Principia Mathematica. Imagine what could have been realized had Brahe given everyone else access during his lifetime.
Data science is all about finding weird wobbles and patterns, and most of it takes enormous amounts of carefully organized information to be useful. For most of the thirteen years that public blockchains have been adding to their ledgers, useful insight has been confoundingly difficult to generate, despite the appearance of complete transparency; the sheer complexity of blockchain data, and the technical expense of maneuvering through the different permutations of smart contracts, differing blockchains and across millions of pseudo-anonymous wallets has made analysis extremely difficult and prevented much of the analysis that powered web 2.0 leviathans like Alphabet and Meta.
At Spectral we believe we’re at the dawn of a new era. Part of a group of analysts, data scientists, platforms, and decentralized applications who are using brute force, artificial intelligence, and advances in data science to build a proverbial bridge to Hven and unlock new insights and applications that will help deliver on the promises of decentralization and data science that have yet to be realized. Web3 is about more than cryptocurrency and owning digital assets—it’s also about stewardship, learning how to use decentralized tooling to make Artificial Intelligence as accessible and equitable as possible.
Blockchains Are A Difficult Data Set
One of the challenges we faced in creating an on-chain creditworthiness assessment score was finding a way to quickly and efficiently process blockchain data. By its nature, blockchain data is hard to process. Grinding through five years of DeFi lending transactions to prune, categorize, and measure data against a machine-learning model in a user-friendly amount of time took our data scientists a combination of intense computing power and a careful balance of data from The Graph, our own Ethereum node and a well-designed data backbone to process.

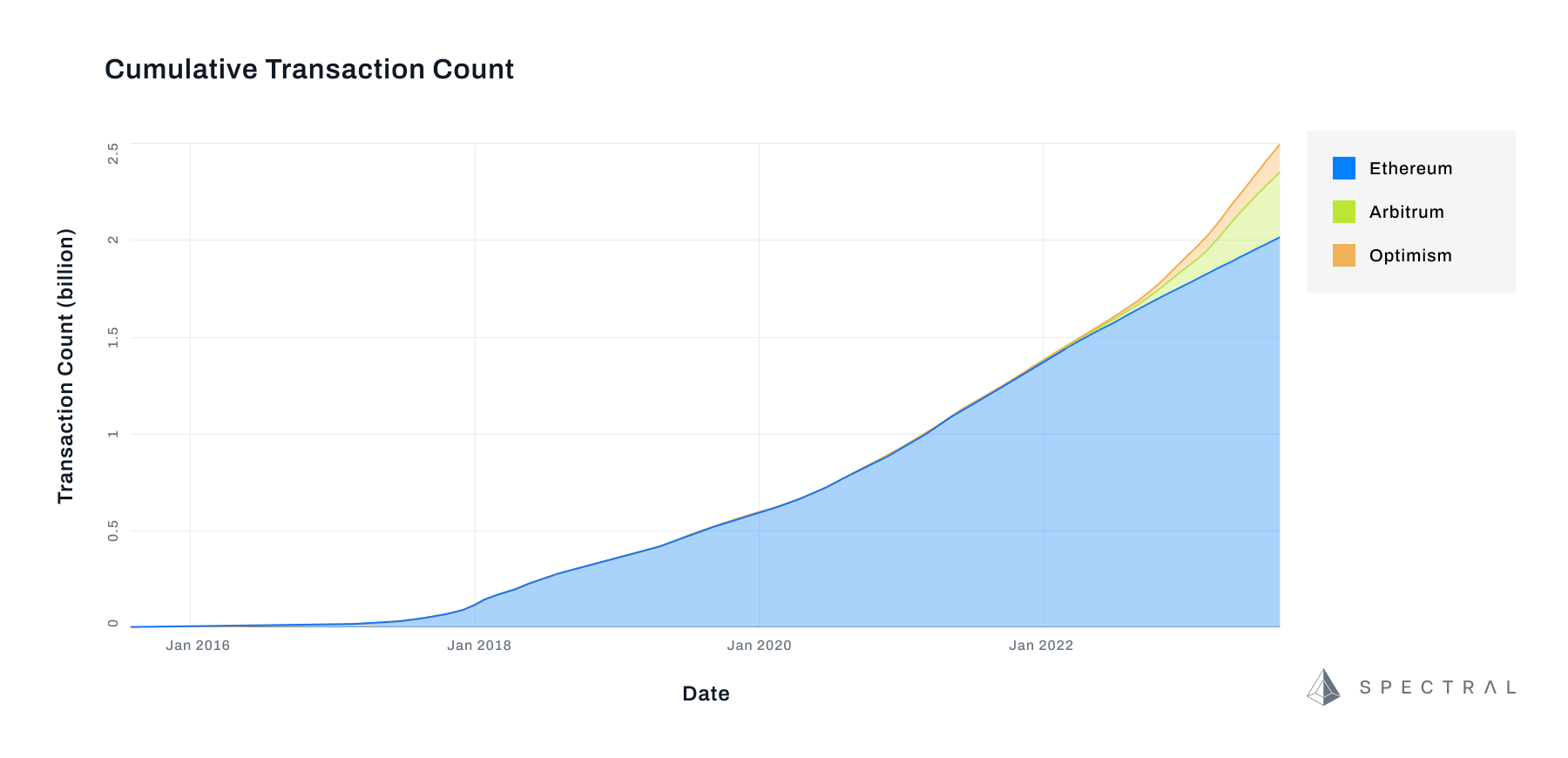
Early on, entire blockchains could easily be downloaded and anyone could stake some ETH and become a node. Today, ten years after Vitalik Buterin first proposed the Ethereum network, over a million transactions a day are executed on the network, 60.9 million smart contracts have been created and an archival node containing all two billion transactions ever executed on-chain weighs in at 12 TB, and it’s growing quickly. Client nodes vary somewhat, with Nethermind at 12TB, Erigon’s at 3TB, and Paradigm’s weighing in at 2TB.
Curling off of individual transactions are the layer 2s, Arbitrum, Optimism and Polygon, and a couple of of others, which skate across the expensive surface of the Ethereum chain by rolling thousands of transactions up into a single one. On-chain data is approaching critical mass, it’s becoming tremendously difficult for individual users or small dApps to sift through blockchain data but the sheer quantity of data available parallels the early days of social media and online commerce, suggesting a tremendous opportunity for anyone capable of adapting modern data science techniques to the task.

Advantages Blockchains Offer Data Scientists
Blockchain data analysis experts Sixdegree think of blockchains as universally accessible databases that are maintained in a decentralized way. This helps data scientists solve a number of practical problems.
Catalin Zorzini outlined some of them in his Machine Learning Masterclass:
How do you ensure the data you’re using is authentic? “Data scientists want data to have built-in authenticity,” Zorzin says. Last year, Equifax accidentally garbled millions of credit scores, affecting mortgage decisions, interest rates, and many other major financial decisions for hundreds of thousands of customers.
Blockchains are designed to prevent double-spending. From a data scientist’s perspective, this means that authenticity is easily verified. Each block “retains a unique ‘fingerprint’... computed using a hash algorithm based on the contents of block.” The integrity of the blockchain depends on the integrity of each of its individual blocks, creating layers of incentives to maintain its integrity and keep out bad actors.
Blockchains also enable data privacy in a number of ways. Protocols that can support smart contracts, i.e. computer programs, can use a variety of sophisticated privacy methods. Homomorphic encryption, for example, “allows computation to be performed on encrypted data,” while federated machine learning, a “collaborative data analysis technique for analyzing data distributively across multiple devices” keeps data models of each distributed unit rather than leaving any part of a data set on a local machine.
A blockchain’s immutable ledger essentially certifies data consistency, and many have economic incentive structures built-in to certify data. For example, some protocols demand stakes and punish (or ‘slash’) nodes providing bad information. The distributed ledger also provides a consistent source of information and a constant flow of real-time information. So long as you can keep up with a node’s mushrooming growth, you can use your data to make real-time decisions.
As scalability improves, data science on the blockchain will become more and more important. Consider the size and fragility of the commercial 5.25” floppy disks sold in the mid-1970s, which held 110KB and were vulnerable to everything from to crinkling to fridge magnets, to a typical higher-end SD Card sold today which can hold several terabytes of information (10s of millions of times more data) with much faster retrieval times.
Spotlight: Spectral’s On-Chain ML Creditworthiness Assessment Model (the MACRO Score)
Last August, We released the beta version of our product, the Multi-Asset Credit Risk Oracle, otherwise known as the MACRO Score. On its surface, the MACRO Score resembled the FICO Score, providing a human-readable three-digit score reflecting a borrower’s risk of defaulting on a loan within 60 days. The model is a machine learning model created from more than 100 unique features, that is individual weights generated from over 100 characteristics, which we referred to as Wallet Signals. These ranged from simple counts of prior liquidations to sophisticated analyses of market volatility and the contents of their wallets.
The MACRO Score is intended as a solution to what might seem like an intractable problem in DeFi lending—how can you loan money to a pseudonymous wallet over a peer-to-peer network without demanding that your borrower stake enough capital to ensure they pay you back (generally about 130% of the amount loaned)? The MACRO Score allows lending protocols to segment their users, offering better terms to better-qualified users.
Our vision for the MACRO Score is to help reduce capital requirements for qualified borrowers in the short term and create more profit opportunities for lending protocols. In the long term, we imagine the MACRO Score and other products derived from it will help pave the way for under-collateralized lending on-chain, and build an alternative credit assessment system that is fully composable, opt-in, and didn’t rely on credit monitoring, or other intrusive, opaque centralized systems.

Beyond Centralized Algorithms: Spectral's Vision for Decentralized, Verifiable Machine Learning Models
In our beta version, we released a single model of the MACRO Score produced by a team of experienced data scientists and credit professionals. The result was extremely fast, capable of reading blockchain information in near real-time, and, measured by a capital efficiency study, which back-tested the model against a year’s worth of data from a lending protocol, was a model that was capable of preserving capital and lending to qualified borrowers at a lower interest rate and with less capital at stake. In other words, the MACRO Score was profitable.
But it wasn’t yet taking full advantage of being built on a blockchain. After all, this model was as opaque as a traditional credit score. We needed a way to guarantee that we were using the algorithm that we had developed to generate our scores (i.e. verifiable computing). After all, trust assumptions also exist for borrowers.
The next step will be to decentralize the model. To do so requires building a decentralized marketplace where user data can be kept private, validated by any user who wants to, and, using benchmarks and a competitive platform, be rewarded for improving on our original model. We're looking at using zero-knowledge machine learning to create a system that's secure, private, and useful as a tool.
Explore our past work on MACRO Score
We’ve devoted the last two years to creating the MACRO Score machine learning model. Read about our journey and some of the technical specifications of what we created here.
- Introduction to the MACRO Score - a brief primer on the Score and its seven main components.
- A Deeper Look at the MACRO Score (Part One) - how we created the model and specific information about the parameters we used to generate it.
- A Deeper Look at the MACRO Score (Part Two) - how we tested and benchmarked our model, with a close look at the metrics involved.
- Proving Capital Efficiency - An in-depth analysis, that simulated the results of a lending protocol using the MACRO Score by back-testing it against a year’s worth of data.
- The State of Zero Knowledge Machine Learning - a glimpse at how zero-knowledge proofs could be used to safeguard data sets and to share work on the blockchain.
Resources and Further Reading
- Verifiable Computing - A lecture about verifiable computation (PDF).
- The MACRO Score - Your personalized web3 credit score. Try for yourself!
- Wallet Signals - Take a closer look at any of the 100+ features used to create the MACRO Score, free API access is available.